


Understanding Process Management: How Operating Systems Handle and Monitor Processes


Before learning about process management first we need to know what is a process. In an operating system, a process is a program in execution. It can be thought of as an instance of a computer program that is being executed by the operating system. A process consists of a set of instructions, data, and resources such as memory, CPU time, input/output devices, and system services. When a program is executed, the operating system creates a process for that program, which has its own memory space and system resources.
Process management means managing different processes. Multiple processes run in our operating system. So there is a need to manage them effectively. Process management involves creating, scheduling, terminating, and monitoring processes. This allows the operating system to manage resources, such as CPU time and memory, and ensure that multiple programs can run simultaneously without interfering with each other.
Process Creation
Process creation involves several steps. The first step is to load the program into memory. This is done by the operating system's loader, which reads the program from disk and allocates memory to hold the program code, data, and stack.
The next step is to set up the process control block (PCB), which is a data structure used by the operating system to manage the process. The PCB contains information about the process, such as its process ID (PID), its current state, its priority, and the resources it is using.
Once the PCB has been set up, the operating system initializes the process's registers and program counter, and the process is ready to be executed. The operating system then adds the process to the process table, which is a list of all the processes currently running on the system.
Processes can be created in several ways. One way is through user interaction, such as when a user runs a program by clicking on an icon or typing a command in a terminal.
Process States
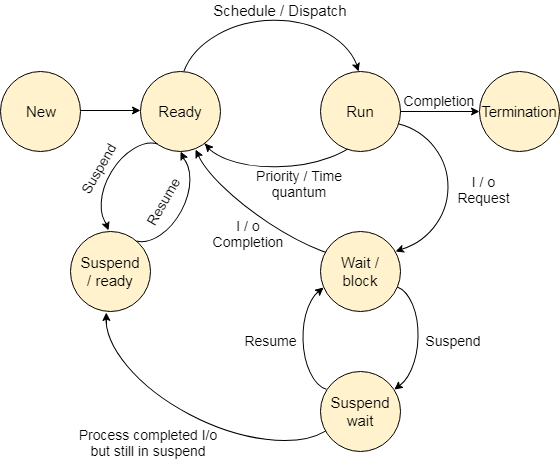
Processes can be in different states, depending on what they are doing and what resources they are using.
The first state is the new state, which is when a process is first created. In this state, the process is initialized and its resources are allocated.
The next state is the ready state, which is when the process is waiting to be executed. In this state, the process has been loaded into memory and is waiting for its turn to run on the CPU.
The running state is when the process is executed on the CPU. In this state, the operating system is executing the instructions of the process, and the process is actively using the CPU.
The waiting state is when the process is waiting for an event or resource to become available. In this state, the process is blocked and is not using any CPU time.
The terminated state is when the process has finished executing and has been removed from memory. In this state, the process's resources have been released, and its PCB is removed from the process table.
The suspended state is a variation of the waiting state, where the process is still waiting for a resource or event, but its PCB has been removed from memory. In this state, the process is not actively using any system resources.
Working:-When a process is first created, it enters a new state. In this state, the operating system initializes the process and allocates resources, such as memory and system hardware, as required by the process. This process will be stored in secondary memory at the beginning.
Once the process has been initialized, it enters the ready state. In this state, the process is loaded into the main memory from the secondary memory and is waiting for its turn to execute. The operating system schedules the process and assigns CPU time as needed.
When the process is assigned CPU time, it enters the running state. In this state, the operating system executes the instructions of the process, and the process is actively using the CPU to perform its tasks.
If the process needs to wait for an event or resource to become available, it enters the waiting state. In this state, the process is blocked and is not using any CPU time. The operating system maintains a list of processes that are waiting for resources or events and schedules them when the resources become available.
When the process finishes executing, it enters the terminated state. In this state, the process's resources are released, and its process control block (PCB) is removed from the process table.
Process Scheduling
Process scheduling is the mechanism by which an operating system selects and assigns CPU time to processes that are waiting to be executed. The scheduling algorithm determines the order in which processes are executed on the CPU. The purpose of process scheduling is to maximize system throughput and minimize response time while ensuring fair allocation of CPU time to all processes.
First-Come, First-Served (FCFS): This algorithm schedules processes in the order they arrive in the ready queue(ie based on arrival time). It is simple but not efficient for systems with many short jobs and long waiting times.
Shortest Job First (SJF): This algorithm selects the process with the shortest estimated processing time[Least burst time which you will learn shortly]. It is optimal for minimizing average waiting time but requires accurate prediction of process runtimes.
Priority Scheduling: This algorithm assigns a priority value to each process and schedules the highest-priority process first. It can result in low-priority processes being starved of CPU time.
Round Robin (RR): This algorithm allocates a fixed time slice to each process in a cyclic order. It provides fair CPU time sharing but may not be efficient for long-running processes.
The choice of scheduling algorithm depends on the specific system requirements and workload characteristics. Modern operating systems often use a combination of algorithms to balance competing goals and provide efficient process scheduling.
In the context of process scheduling, Arrival time(at), Turnaround Time (TAT), Waiting time(wt), Completion time(ct), and Burst time(bt) are important metrics that are used to measure the performance of different scheduling algorithms. Here is a brief explanation of each of these metrics:
Arrival Time (AT): The arrival time is the time at which a process enters the system and requests CPU time for execution. AT is an important input parameter for the scheduling algorithm, as it helps to determine the order in which processes are scheduled for execution.
Turnaround Time (TAT): The turnaround time is the time it takes for a process to complete execution, i.e., from the time the process enters the system to the time it finishes executing. TAT is calculated as the difference between the completion time and the arrival time of the process. A low TAT indicates a fast response time and efficient utilization of system resources.
Burst Time (BT): BT is the amount of time that a process requires to complete its execution once it starts running on the CPU.
Waiting Time (WT): The waiting time is the amount of time a process spends waiting in the ready queue before it is executed. WT is calculated as the difference between the TAT and the burst time of the process. A low WT indicates efficient process scheduling and minimizes idle time.
Completion Time (CT): The completion time is the time at which a process finishes execution, i.e., the time at which the process completes all its CPU and I/O operations. CT is equal to the sum of the arrival time, waiting time, and burst time of the process.
Preemptive and non-preemptive scheduling
Preemptive Scheduling: In preemptive scheduling, a running process can be interrupted by the operating system to allocate the CPU to another process with higher priority or to respond to an event. The CPU is allocated to a process for a fixed time slice, and if the process does not complete its execution during that time, it is preempted, and the CPU is allocated to another process. Preemptive scheduling provides better response times and ensures that higher-priority processes get the required CPU time. It is suitable for real-time systems and multi-tasking environments, where multiple processes need to be executed concurrently.
Eg:-round robin, priority(when a higher priority process comes lower priority process will be interrupted), SJF(when a processFCFS with lower burst time comes)
Non-Preemptive Scheduling: In non-preemptive scheduling, a running process cannot be interrupted by the operating system until it completes its execution or waits for an event such as I/O. The CPU is allocated to a process for its entire execution time or until it waits for I/O, and the process must release the CPU voluntarily. Non-preemptive scheduling provides a simpler and more predictable execution model, but it can result in lower system responsiveness and priority inversion problems. It is suitable for systems with short and predictable task durations, where the overhead of context switching(switching of cpu from one process to another process) is significant.
Eg:-FCFS
Interprocess communication
Interprocess Communication (IPC) is a mechanism that allows different processes to communicate and exchange information with each other. IPC is an essential component of modern operating systems, as it enables the sharing of resources and coordination between different software components. There are 2 fundamental types of IPC:
Shared Memory: Shared memory is a mechanism that allows multiple processes to access the same region of memory. This approach is often used for high-speed data exchange between processes. In this mechanism, a portion of memory is mapped into the address space of multiple processes, allowing them to read and write to the same memory region. Shared memory provides fast and efficient communication, as it eliminates the overhead of copying data between processes. However, it requires careful synchronization and management to avoid conflicts and race conditions(It is an undesirable situation that occurs when a device or system attempts to perform two or more operations at the same time).
Message Passing: Message passing is a mechanism that allows processes to communicate by sending and receiving messages. In this approach, a process sends a message to a specific destination process, and the receiving process reads and processes the message. Message passing is a flexible and secure mechanism, as it allows processes to communicate independently of their physical locations or the underlying hardware. However, it can be slower than shared memory, as messages need to be copied between processes, and it requires more overhead for message queue management and synchronization.
Process synchronization
Process synchronization is an essential concept in operating systems that deals with coordinating access to shared resources between multiple processes. When multiple processes are accessing the same shared resource, such as a file or a printer, there can be conflicts that lead to race conditions, data inconsistency, and other issues. To prevent these problems, processes need to synchronize their access to shared resources, and operating systems provide various mechanisms for process synchronization.
Mutexes: Mutexes are a synchronization mechanism that allows processes to acquire exclusive access to a shared resource. A mutex is a binary semaphore that can be locked by one process at a time. When a process locks a mutex, no other process can access the resource until the mutex is released. Mutexes are commonly used to protect critical sections of code, where only one process can execute at a time.
Semaphores: Semaphores are a synchronization mechanism that allows processes to coordinate their access to shared resources. A semaphore is a counter that can be incremented or decremented by processes. When a process wants to access a shared resource, it must first acquire the semaphore by decrementing its value. If the semaphore value is zero, the process must wait until another process releases the semaphore by incrementing its value. Semaphores can be used to implement critical sections, bounded buffers, and other synchronization scenarios.
Monitors: Monitors are a high-level synchronization mechanism that provides a structured way for processes to access shared resources. A monitor is an abstract data type that encapsulates a shared resource and the methods to access it. Only one process can access a monitor at a time, and the monitor handles the synchronization internally. Monitors can be used to implement complex data structures and algorithms, where multiple processes need to cooperate to achieve a common goal.
Condition Variables: Condition variables are a synchronization mechanism that allows processes to wait for a specific condition to be true before accessing a shared resource. A condition variable is associated with a mutex and allows processes to wait on it until a signal is sent by another process. When a process wants to access a shared resource, it first locks the associated mutex, checks the condition, and if it is false, it waits on the condition variable. When another process updates the shared resource and signals the condition variable, the waiting process is woken up and can access the shared resource.
In next blog I will be writing about Memory management. So subscribe to my blog for free to get more updates and articles related to computer science and software development. If there are any suggestions about my contens like improving quality of content,way of presenting or explanations ,feel free to contact me in twitter or linkedin or mention it in the comment section.
HAPPY LEARNING JOURNEY